Windows 文本文件的字符集和编码研究
Nov 5, 2015 • 1 min readWindows 环境下文本文件的字符集和编码是比较特殊的,因此在编程中使用 Windows 环境下的文本文件时容易出现问题。需要申明的一点是字符集(character set)与编码(encoding)是两个概念。
首先介绍几个名词:
- ASCII 是一套基于拉丁字母的字符集和编码系统,等同于 ISO/IEC 646 标准,定义了 128 个字符,其中包括 33 个控制字符。使用一个字节的7位来表示 128 个字符,0x00-0x7F,最高位为 0。其局限在于只能显示 26 个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语。
- Unicode 是在通用字符集(UCS,ISO/IEC 10646)的基础上发展的一套系统。其实现方式有 UTF-16,UTF-32 和 UTF-8。UTF-16 采用两个字节来表示,对应于 UCS-2,每一个字符采用 U+hhhh 来表示,其中每一个 h 代表一个十六进制数。UTF-32 采用四个字节来表示,对应于 UCS-4。对于多个字节的表示,需要确定字节的顺序(高低位),于是引入 BOM(Byte Order Mask)。UTF-16 的大端序(Big Endian)的表示形式为 U+FEFF,小端序(Little Endian)为 U+FFFE。此 BOM 出现在文件的最开始。由于采用 UTF-16 或 UTF-32 会浪费空间,于是变长度字符编码 UTF-8 在互联网上得到广泛使用。
- UTF-8 的编码有一定的形式,可以将统一字符的 UTF-16 编码转换成 UTF-8 编码。参见图 1。例如汉字 “备” 的 UTF-32 大端序编码为 U+5907,二进制形式为 01011001 00000111(两个字节)。对于 UTF-8 编码则需要三个字节,将 01011001 00000111 分成 4 个 x,6 个 y 和 6 个 z,即 0101 100100 000111,分别写入到 1110xxxx 10yyyyyy 10zzzzzz中,于是得到11100101 10100100 10000111,其十六进制数为0xE5 A4 87。
- GB2312 是一种简体中文字符集,采用 EUC-CN 来编码。后续的是 GBK 和 GB18030,两者采用不同的编码形式。因此通常说此三者是字符集和编码连锁的方案。例如汉字 “备” 的 GBK 编码为 0xB1 B8。
- Code Page 代码页是字符集编码的别称,主要在 Windows 中使用。例如 437(最初的 IBM PC 代码页,实现了扩展 ASCII 字符集),936(简体中文 GBK),1200(UTF-16 LE),1201(UTF-16 BE),65001(UTF-8)。
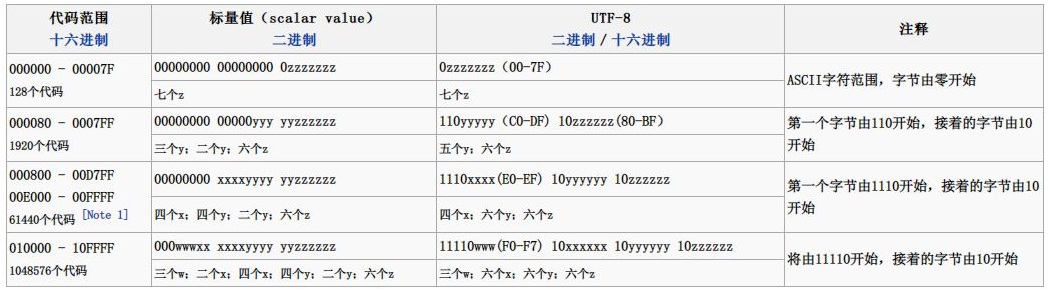 UTF-8 编码
UTF-8 编码
对于 Windows,其内核采用 UTF-16 编码,但 Windows 采用了区域(locale)来决定具体的编码,也即是 Windows 下所谓的 ANSI,例如简体中文的 Windows 采用的是 GBK。
采用记事本生成的文本文件可以有四种编码形式:
- ANSI,GBK 或者是 936。
- UTF-16 LE,以 0xFF FE 开始。
- UTF-16 BE,以 0xFE FF 开始。
- UTF-8,需要注意的是 Windows 下的 UTF-8 编码会有 BOM,即在文件的开始有 0xEF BB BF。这一点容易出现问题,一般的 UTF-8 编码是没有 BOM 的。
另外需要注意的是:
- Windows 下的换行有两个字符(CR+LF)回车和换行,其代码为 0x0D 0A。
- cmd.exe 中使用 chcp xxx 来修改代码页,但命令提示符不支持 chcp 1200 和 chcp 1201,而且在支持 UTF-8 时需要修改显示的字体(Lucida Console),因为点阵字体不适用 Unicode 编码。